BERT复现-详解Attention
本篇文章介绍使用PyTorch实现BERT中的Self-Attention,本文适用范围:阅读过transformer和bert论文,了解其架构,但是不了解其代码实现的学习者
BERT中的Self-Attention架构
BERT中的Self-Attention使用的是与Tranformer中相同的架构,在transformer论文中其示意图如下:
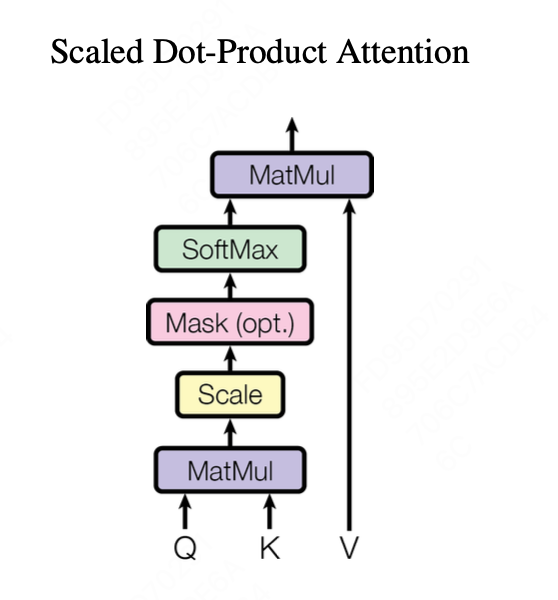
其公式表述为 $Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
因此其输入为Query、Key、Value三个Tensor, 其大小为[batch_size, head_num, seq_len, d_model/head_num], 其中d_model/head_num表示多头中拆分到每一个头里的参数大小head_size,seq_len表示文本长度,以及可选的mask,输出为这几个向量经过多次运算后的值。
整体流程如下:
- 首先Query与Key之间进行矩阵乘法,将Key的Size调整为[batch_size, head_num, d_model/head_num, seq_len], 相乘后得到大小为[batch_size, head_num, seq_len, seq_len]的tensor
- 然后做scale,即除以$\sqrt{head_size}$ 前两步合并,即代码:
1
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))
- Mask操作通过tensor自带的mask_fill方法实现,该函数会根据mask中为1的元素所在的索引,在tensor中相同的的索引处替换为特定的value。此处将所有mask为0处的值替换为1e-9,在softmax时其值会趋近于0。
1 2
if mask is not None: scores = scores.masked_fill(mask == 0, -1e9)
- 然后是Softmax操作,指定维度为-1
1
p_attn = F.softmax(scores, dim=-1)
- 最后p_attn与value做矩阵乘法, 结果的Size仍为为[batch_size, head_num, d_model/head_num, seq_len]
因此最终代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import torch.nn as nn
import torch
import math
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self):
super().__init__()
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
至于为什么要返回一个p_attn,这就涉及到cross-attention的操作了,后续会写文章阐明
This post is licensed under CC BY 4.0 by the author.