BERT复现-详解PositionEmbedding
talk is cheap, show me the code
首先看transformer原文中的定义: 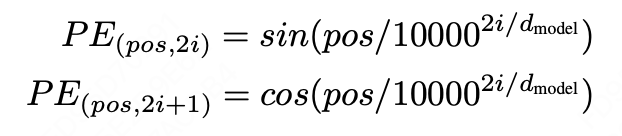
PE是一个(max_len, d_model)的Tensor,其中每个位置的值由如上公式定义,其中pos表示单词的位置,i是纬度。 代码实现上来说,先构建position,令其为torch.arange(0, max_len)的序列,然后增加维度。再构建分母部分的div_term, div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()。 二者相乘后分别取sin、cos值进行填入即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
除此之外,位置编码还可以采用可学习的embedding形式,如下代码所示
1
2
3
4
5
6
7
8
9
10
11
12
13
class PositionEmbeddings(nn.Module):
def __init__(self, config):
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
def forward(self, input_ids, token_type_ids=None):
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
position_embeddings = self.position_embeddings(position_ids)
return position_embeddings
This post is licensed under CC BY 4.0 by the author.