LayerNormalization
今天和同学讨论transformer源码的时候发现了自己竟然说不出来layer normalization是怎么做的,继续深究的时候发现了一个更神奇的地方,就是自己实现的layernormalization和pytorch官方的怎么都不一样,最后发现是因为求方差时选择样本方差还是总体方差的问题,因此写篇博客记录下该问题
给定一个维度是(batch_size, seq_len, hidden_size)的张量,LayerNormalization和BatchNormalization到底是怎么做的呢?或者说,他们在做scale时,求的哪些值的均值的方差呢?
1
2
3
import torch
batch_size, seq_len, hidden_size = 2, 3, 5
x = torch.randn([batch_size, seq_len, hidden_size])
首先说BatchNormalization,借用LayerNormalization原文中的公式 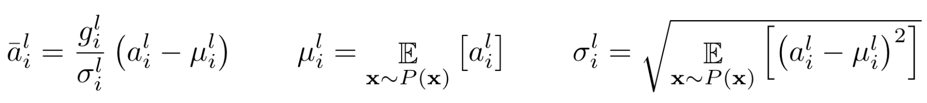 其中 $a_{i}^{l}$ 是第l层中第i维的值,即hidden_size该维中的第i个,因此BatchNorm所做的就是,对于hidden_size中的每一维,都计算它在不同batch、不同seq_len中的均值和方差,然后做scale。也就是说同一hidden_state的维度、不同batch和seq_len,共用相同的均值和方差
其中 $a_{i}^{l}$ 是第l层中第i维的值,即hidden_size该维中的第i个,因此BatchNorm所做的就是,对于hidden_size中的每一维,都计算它在不同batch、不同seq_len中的均值和方差,然后做scale。也就是说同一hidden_state的维度、不同batch和seq_len,共用相同的均值和方差
从代码上来说就是
1
2
3
4
5
6
7
8
mean = x.mean([0, 1], keepdim=True)
std = x.std([0, 1], keepdim=True, correction=0)
z = (x - mean) / (std + 1e-5)
print(z.view(batch_size, seq_len, hidden_size))
layer = torch.nn.BatchNorm1d(5,eps=1e-5)
y = layer(x.view(-1, 5))
print(y.view(batch_size, seq_len, hidden_size))
此处两个结果相同,说明batchnorm其实就是在对hidden_size的一个维度上,计算其他维度上均值和方差,然后做scale
再说layerNormalization,原文中的公式如下 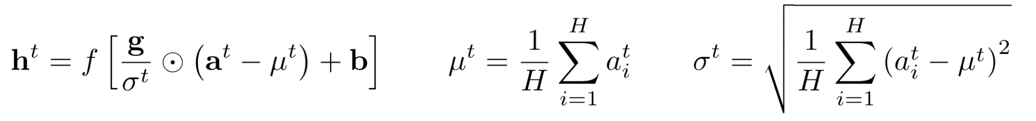 与batchnorm相比,它是对整个hidden_state去求均值和方差然后做scale,同一batch、同一seq_len,共用相同的均值和方差
与batchnorm相比,它是对整个hidden_state去求均值和方差然后做scale,同一batch、同一seq_len,共用相同的均值和方差
从代码上来说
1
2
3
4
5
6
7
8
9
10
11
mean = x.mean([-1], keepdim=True)
std = x.std([-1], keepdim=True, correction=0)
z = (x - mean) / (std + 1e-5)
layer = torch.nn.LayerNorm([5],eps=1e-5)
y = layer(x)
print(y)
print(y.shape)
print(z)
print(z.shape)
求均值和方差只需要对最后一维(hidden_state维)求即可
两种正则化方法的对比图如下 
其实这里还有一个点,就是在求标准差时,用了correction=0这个参数,这是因为std默认求的是样本标准差,是经过贝塞尔校正的,也就是其分母为n-1而不是n。LayerNorm和BatchNorm默认求的是总体标准差,也就是没经过校正的。
参考: stackoverflow的一篇解释帖 https://stackoverflow.com/questions/70065235/understanding-torch-nn-layernorm-in-nlp
LayerNorm原论文 https://arxiv.org/pdf/1607.06450.pdf